Hello everyone! Today I want to talk to you about one of the projects I’ve been following most closely lately. It’s an initiative that, honestly, I believe has a huge future ahead of it, and one I’m committed to supporting however I can. Not just by giving it visibility, but by contributing directly to the code to help it reach its full potential.
I’m talking about Sail, from the team at LakeSail.
In seas ruled by sea giants and lightning storms, where the echoes of Thor’s hammer still shake the skies, Sail moves forward like an agile, precise drakkar.
While others summon sparks with noise and force, Sail sails light, free from unnecessary weight, powered by the raw force of efficiency, cutting through the sea with control and determination.

What is Sail? #
As explained in its documentation:
Sail ⛵ is an open-source compute engine designed for both single-node and distributed environments. Its mission is to unify batch processing, real-time workloads, and compute-intensive tasks (such as AI).
If you’re already using Apache Spark, you can switch to Sail without changing your Spark code, and benefit from the advantages of a modern programming language like Rust, as well as a system designed for the realities of today’s compute landscape.
Sail is well-positioned within the composable data stack. It’s built on solid foundations like Apache Arrow for in-memory data representation, and Apache DataFusion as the query engine. It’s also working toward integrations with the Ibis DataFrame library, lakehouse formats, and various cloud storage engines.
The vision is simple: Sail helps you unlock large-scale value from your data, no matter how or where it’s stored.
Why Sail? #
The key to Sail lies in the technologies it’s built on: Apache DataFusion, and more fundamentally, Apache Arrow. To understand why we chose them, let’s first look at what each brings to the table.
Apache Arrow is an open, language-agnostic specification for in-memory columnar data. In simple terms, Arrow organizes data by columns instead of by rows, which allows modern CPUs and GPUs to reach their full performance potential. This format supports high-bandwidth sequential memory access, better cache affinity, and efficient vectorization using SIMD instructions. In practice, this means analytic algorithms can execute much faster on Arrow-formatted data.
Apache Arrow y el modelo columnar #
In a columnar format, data is stored grouped by columns, not by rows. That means all values of a single column live together in memory, one after another, in a homogeneous buffer. This contrasts with traditional row-based layouts, where each row stores mixed fields of different types side by side. For example, in Apache Spark, each task usually processes a partition made up of multiple full rows (with all their fields bundled). Arrow, on the other hand, allows each compute unit to process one column at a time, operating on a single data type for all values.

In summary, Arrow’s columnar layout brings key advantages:
-
Sequential, cache-friendly access: Operators scan memory linearly, minimizing cache misses and random access.
-
Automatic vectorization: With homogeneously typed buffers, SIMD (Single Instruction, Multiple Data) instructions can process hundreds of values per clock cycle.
-
Zero-copy interoperability: A column created in C++ can be consumed directly from Python, Rust, or Java, without serialization or data duplication.
Because Arrow simplifies data access by making it homogeneous and contiguous in memory, it enables execution engines that are much lighter and faster than row-based ones, eliminating overhead and taking full advantage of the hardware.
Apache DataFusion #
Apache DataFusion is a query execution engine written in Rust, fully built on top of Apache Arrow’s in-memory format.
Thanks to this columnar model, DataFusion runs SQL queries with high efficiency, avoiding costly conversions and leveraging SIMD vectorization. It can run both in a single process and across distributed environments, all while using the same columnar data representation.
It comes with native SQL and DataFrame APIs, built-in support for formats like CSV, Parquet, JSON, and Avro, Python bindings, and a flexible, extensible architecture backed by an active community.
use datafusion::prelude::*;
use datafusion::error::Result;
#[tokio::main]
async fn main() -> Result<()> {
// Create a new dataframe with in-memory data using macro
let df = dataframe!(
"a" => [1, 2, 3],
"b" => [true, true, false],
"c" => [Some("foo"), Some("bar"), None]
)?;
df.show().await?;
Ok(())
}Apache DataFusion is part of several noteworthy subprojects, including:
-
DataFusion Python, a Python interface for running SQL and DataFrame queries, with a developer experience very similar to Pandas.
-
DataFusion Comet, an accelerator for Apache Spark built on top of DataFusion. We’ll dive deeper into this project in a future blog post.
Alright, but… what about Sail? #
With all this context, where does Sail fit in?
Sail acts as a bridge between data scientists used to working with PySpark and companies whose analytics infrastructure and production pipelines are built around PySpark applications.
What Sail offers is a familiar PySpark-like experience, reusing the same syntax, but under the hood, it replaces Spark’s execution engine with Apache DataFusion, and therefore leverages Apache Arrow as its in-memory data format.
Snippet Code (PySpark)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Create a Spark session using Spark Connect (remote Spark cluster)
spark = SparkSession.builder \
# .master("local[*]") \ # (Local) Uncomment for local mode
.remote("sc://remote-host:15002") \ # (Remote) Address of the remote Spark Connect server
.appName("RemotePySparkApp") \
.getOrCreate()
# Example: read a Parquet file
df = spark.read.parquet("/data/users.parquet")
# Perform a basic transformation
df.filter(col("age") > 30).select("name", "email").show(truncate=False)
# Stop the Spark session
spark.stop()Snippet Code (Sail)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Create a Spark session using Spark Connect (remote Spark cluster)
spark = SparkSession.builder \
.remote("sc://remote-host:50051") \ # (Remote) Address of the remote Sail server
.appName("RemotePySparkApp") \
.getOrCreate()
# Example: read a Parquet file
df = spark.read.parquet("/data/users.parquet")
# Perform a basic transformation
df.filter(col("age") > 30).select("name", "email").show(truncate=False)
# Stop the Spark session
spark.stop()The port is configurable, it can be the same if needed.
This approach eliminates many of the costs associated with the traditional stack: no need for a Spark cluster, no JVM, no complex serialization steps.
The result? Applications that are lighter, faster, with no garbage collector, no startup latency, and minimal resource consumption—all thanks to an engine written in Rust and executed entirely in memory.
Additionally, the Sail team has published official benchmarks comparing query performance against Spark, showing notable improvements in execution time and overall efficiency.
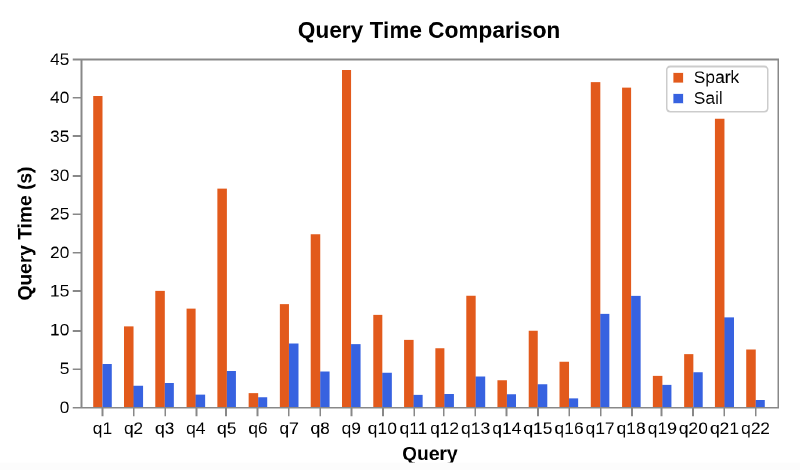
My Bet on the Future of Data Engineering #
I’ve said it more than once on LinkedIn, and I’ll keep saying it: I firmly believe Apache DataFusion and Sail are the next big step in data engineering.
Many companies are currently investing heavily in platforms like Databricks, which makes sense, considering it’s the company behind Apache Spark and offers a powerful ecosystem. But as a technical practitioner and a critical observer of the industry, I can’t help but feel we’re losing focus.
Do we really need that much infrastructure? #
More and more often, I see how convenience and habit are leading us to normalize heavy, bloated deployments: “I’ll just launch my PySpark job. I’ve got cores and machines, it’ll run.”
This mindset, while practical in the short term, often comes with hidden costs, inefficiencies, and a false sense of scalable robustness.
As Ángel Álvarez Pascua and David López González pointed out during their joint meetup on Spark performance and optimization, optimization isn’t just about tuning partitions or choosing the right file format. Optimization happens on many levels: infrastructure, data, and yes, the framework itself.
Time to Rethink Our Stack #
Unpopular opinion: Apache DataFusion and Sail could (and maybe should) be the future of data engineering.
Why?
-
They’re written in Rust: a modern, safe, and blazing-fast programming language.
-
They’re designed for vectorized execution, making efficient use of modern hardware.
-
They’re lightweight, modular, and embeddable, breaking free from the heavy, monolithic JVM-based stacks.
Just as we once moved from relational databases to Spark in search of scalability, perhaps it’s time to rethink our data stack once again.
It’s time to move away from heavyweight, JVM-bound giants toward solutions built on modern principles: speed, simplicity, and efficiency.
I’m not saying Spark is dead, not at all! But I do believe that for many real-world use cases, we no longer need a full cluster just to perform basic transformations or exploratory analysis. And that alternative is called DataFusion. And the gateway to adopting it in the real world? Sail.